TL;DR: on visually-degraded documents, GPT-5.4 and GPT-5.5 hallucinate numeric values at 2 to 3 times the rate of Opus 4.7 and Sonnet 4.6 at matched default effort (all four with thinking off). When Anthropic models can't read a field cleanly they return null, which is the right move. OpenAI models fill in a plausible-looking number instead. Rerunning at matched HIGH and XHIGH reasoning effort (which is also where Gemini 3.1 Pro can fairly come back in, since it has no thinking-off mode) narrows the gap but doesn't close it: GPT-5.4's numeric rate falls to 8.6% at HIGH and 8.8% at XHIGH against an Anthropic and Google baseline that lands between 3% and 5.4%. GPT-5.5 doesn't respond to thinking effort; its numeric rate is flat across all three effort levels (11.4% → 10.7% → 10.7%) and at HIGH and XHIGH actually exceeds GPT-5.4's.
| Metric | GPT-5.5 | GPT-5.4 | Opus 4.7 | Sonnet 4.6 |
|---|---|---|---|---|
| Numeric hallucination rate | 11.4% | 11.9% | 3.4% | 5.2% |
| String hallucination rate | 5.8% | 5.9% | 2.5% | 3.1% |
| Fabricated values per document | 5.5 | 5.8 | 2.2 | 3.2 |
Gemini 3.1 Pro isn't in this default-effort table. Its API has no thinking-off mode (default is HIGH), so a default-vs-default row wouldn't be a matched comparison. It reappears in the matched HIGH and XHIGH tables later on in this post.
| Comparator | GPT-5.4 worse | GPT-5.4 better | Ties |
|---|---|---|---|
| vs GPT-5.5 | 36 | 33 | 79 |
| vs Opus 4.7 | 63 | 13 | 72 |
| vs Sonnet 4.6 | 57 | 22 | 69 |
On 27 of the 148 documents, GPT-5.4 hallucinates more than all three comparators at matched thinking-off (GPT-5.5, Opus 4.7, Sonnet 4.6); on only 5 does it hallucinate less than all three. The GPT-5.5 row is the only paired matchup where GPT-5.4 comes close to parity (36 worse, 33 better), which says less about GPT-5.4 improving and more about GPT-5.5 not.
Exact-match evals against flat field values won't catch any of this. The OpenAI outputs look fine in isolation: the currency is well-formed, the rows match the schema, and the numbers tie back to each other cleanly. You need labeled adversarial ground truth plus paired-comparison scoring across models to see this kind of failure at all, which is why I'm building Aginor.
The $42M financial statement
The N3 financial statement reports $42.0M of annual revenue. Both OpenAI models read the visible gross-profit line correctly at $19.56M, then hallucinated the revenue and COGS lines underneath it. GPT-5.5 reported $35.21M of revenue and $15.66M of COGS. Those two numbers subtract to exactly $19.56M, the correct gross profit. The arithmetic ties out; a flat schema or sanity-check pipeline won't catch it. GPT-5.4 went further: it reported $21.65M of revenue (off by $20.4M, almost half the real value) and a net income of $1.67M (off by 48% from the actual $3.22M). Opus 4.7, Sonnet 4.6, and Gemini 3.1 Pro all returned the correct $42.0M revenue. Opus and Gemini got every line item exact; Sonnet's net income came back $7,500 over and its interest expense $500 light.
When the Anthropic models can't read a value cleanly they return null. They didn't have to here on N3, but they do on harder N4 and N5 documents elsewhere in the corpus. The OpenAI failure mode is the opposite: fabricate a plausible-looking number and tie the rest of the income statement back to it.
| Line item | Actual | GPT-5.5 | GPT-5.4 | Opus 4.7 | Sonnet 4.6 |
|---|---|---|---|---|---|
| Revenue | $42.0M | $35.2M | $21.6M | $42.0M | $42.0M |
| COGS | $22.4M | $15.7M | $18.9M | $22.4M | $22.4M |
| Gross profit | $19.56M | $19.56M | $19.56M | $19.56M | $19.56M |
| Interest expense | $0.95M | $1.78M | $0.95M | $0.95M | $0.95M |
| Net income | $3.22M | $2.71M | $1.67M | $3.22M | $3.23M |
GPT-5.5 raw output, income statement section, abridged:
"income_statement": {
"revenue": {
"gross_revenue": null,
"net_revenue": 35211000
},
"cost_of_goods_sold": 15655200,
"gross_profit": 19555800,
"operating_income": 5089400,
"interest_expense": 1783000,
"income_before_tax": 3306400,
"income_tax": 595200,
"net_income": 2711200
}Revenue minus COGS = $35,211,000 minus $15,655,200 = $19,555,800. That matches the gross profit line exactly. The two hallucinated values are constructed to tie back to the one real value the model could see on the page.
See it yourself: rendered PDF · ground truth · all five model extractions (default / HIGH / XHIGH)
The ACORD 45 property schedule
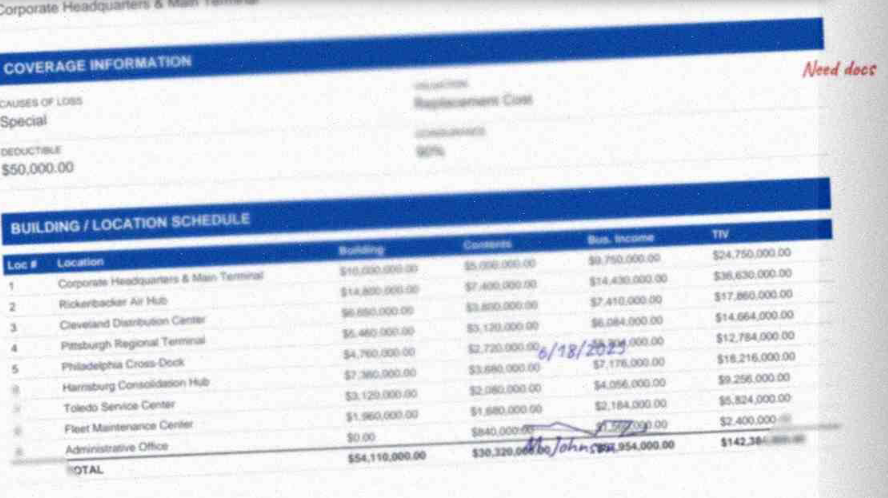
The N5 ACORD 45 schedules 9 buildings that sum to a total insured value of $54.11M. Opus 4.7, Sonnet 4.6, and Gemini 3.1 Pro each returned all 9 rows accurately, with three small misses across the three models (Gemini row 3 off by $10k, Opus and Sonnet row 6 each off by $20k). None of them rewrote a row by millions. Both OpenAI models did.
GPT-5.5 returned 9 rows with the right location names, but 7 of the 9 building values are wrong. Row 2 ("Rickenbacker Air Hub") comes back at $11.4M instead of the actual $14.8M. Rows 3, 4, 7, and 8 are each off by hundreds of thousands or low millions. The total ties out to $54.11M exactly. Seven hallucinated rows that sum to the right grand total: summing the column won't catch it.
GPT-5.4 is worse. It reports $102.4M of building value on row 1 for a building actually worth $10M, $24M on row 2 for a $14.8M building, and is off on 8 of 9 rows total. The grand building total comes back at $159.06M against an actual $54.11M, off by $105M. It also got the row 6 location name wrong (reported "Hamburg Consolidation Hub" instead of "Harrisburg Consolidation Hub").
| Row | Actual | GPT-5.5 | GPT-5.4 | Opus 4.7 | Sonnet 4.6 |
|---|---|---|---|---|---|
| 1 (HQ) | $10.00M | $10.00M | $102.40M | $10.00M | $10.00M |
| 2 (Rickenbacker) | $14.80M | $11.40M | $24.00M | $14.80M | $14.80M |
| 3 (Cleveland) | $6.65M | $8.40M | $9.60M | $6.65M | $6.65M |
| 4 (Pittsburgh) | $5.46M | $6.40M | $6.80M | $5.46M | $5.46M |
| 5 (Philadelphia) | $4.76M | $4.70M | $4.30M | $4.76M | $4.76M |
| 6 (Harrisburg) | $7.36M | $7.30M | $7.20M | $7.38M | $7.38M |
| 7 (Toledo) | $3.12M | $3.22M | $3.20M | $3.12M | $3.12M |
| 8 (Fleet maint.) | $1.96M | $2.69M | $1.56M | $1.96M | $1.96M |
| 9 (Admin office) | $0 | $0 | $0 | $0 | $0 |
| Total | $54.11M | $54.11M | $159.06M | $54.11M | $54.11M |
GPT-5.5 raw output, rows 1 and 2 (abridged):
"locations": [
{
"location_number": "1",
"address": "Corporate Headquarters & Main Terminal",
"building_value": 10000000,
"contents_value": 5000000,
"bi_value": 9750000,
"tiv": 24750000
},
{
"location_number": "2",
"address": "Rickenbacker Air Hub",
"building_value": 11400000,
"contents_value": 7400000,
"bi_value": 9000000,
"tiv": 27800000
},
...
]The hallucination here is not in the names or the totals. It's in the per-row values, hidden by a grand total that happens to be right. An invoice-reconciliation pipeline that checks column sums will pass this output through clean.
See it yourself: rendered PDF · schedule ground truth · full packet ground truth · all five model extractions (default / HIGH / XHIGH)
Reasoning level data
I reran the 148-document test at three reasoning-effort levels for each model: default, HIGH, and XHIGH (Sonnet's XHIGH-equivalent is effort=max, its ceiling).
| Model | Default | HIGH | XHIGH |
|---|---|---|---|
| GPT-5.5 | 11.4% | 10.7% | 10.7% |
| GPT-5.4 | 11.9% | 8.6% | 8.8% |
| Opus 4.7 | 3.4% | 4.6% | 4.2% |
| Sonnet 4.6 | 5.2% | 4.7%† | 3.1%‡ |
| Gemini 3.1 Pro | 3.2% | 5.4% | 4.0% |
| Model | Default | HIGH | XHIGH |
|---|---|---|---|
| GPT-5.5 | 5.8% | 6.7% | 5.9% |
| GPT-5.4 | 5.9% | 4.5% | 4.0% |
| Opus 4.7 | 2.5% | 2.5% | 3.1% |
| Sonnet 4.6 | 3.1% | 3.0%† | 2.7%‡ |
| Gemini 3.1 Pro | 3.7% | 3.6% | 2.9% |
† Sonnet HIGH: n=147 (1 doc timed out). ‡ Sonnet XHIGH: n=144 (4 docs timed out). See "Timeouts" below.
Thinking effort doesn't behave the same way across models. GPT-5.4 picks up modest gains: numeric drops 11.9% → 8.6% → 8.8% (HIGH and XHIGH cluster together) and string drops 5.9% → 4.5% → 4.0%. GPT-5.5 doesn't budge: numeric is flat across all three levels (11.4% / 10.7% / 10.7%) and string is flat-to-up (5.8% / 6.7% / 5.9%). At HIGH and XHIGH, GPT-5.5 actually hallucinates numbers more than GPT-5.4. Sonnet 4.6 is the one model that shows a clear monotonic improvement with thinking (5.2% → 4.7% → 3.1% numeric), albeit on partial denominators at the top end (XHIGH dropped 4 docs to timeouts; HIGH dropped 1). Opus 4.7 actually regresses with thinking (3.4% → 4.6% → 4.2%), and Gemini 3.1 Pro is non-monotonic (3.2% → 5.4% → 4.0%).
At matched HIGH, GPT-5.4 hallucinates numbers at 8.6% and GPT-5.5 at 10.7%, against Opus 4.7's 4.6%, Sonnet 4.6's 4.7%, and Gemini 3.1 Pro's 5.4%. The OpenAI-vs-baseline gap narrows from ~2-3x at default to ~2x at HIGH for both models.
What's actually in Nightmare
148 documents across 5 difficulty levels (N1 clean digital up to N5 corruption plus handwriting plus cross-document mismatches), 9 categories spanning ACORDs, SOVs, loss runs in PDF/CSV/XLSX, dec pages, engineering reports, financial statements, driver schedules, narratives, and hybrid workbooks. The generator emits the PDF or XLSX and the ground-truth JSON in the same pass, so the labels are the same data that rendered the document. No labeling step. Prompts, schemas, and scoring code live in the public repo.
Other findings
Failures are quiet
Across all five models, 31% of extractions scored below 0.5 composite without ever tripping a catastrophic-error flag, and only 1% crossed the catastrophic threshold at all. Your production pipeline isn't going to break in any obvious way on these documents. It's going to degrade field by field, underneath whatever review threshold you've trained your reviewers on, and you won't notice unless you're actively looking.
No hero model on raw accuracy
Overall composite scores cluster at 0.64 to 0.68 across all five frontier models at default effort. The actual signal between these models lives in the hallucination rate, not in the composite and not in the catastrophic-flag count.
Per-document output volume
The five models do not emit the same number of values per document. At default effort, GPT-5.5, GPT-5.4, and Gemini 3.1 Pro check roughly 32 strings and 32-33 numbers per document on average, while Opus 4.7 and Sonnet 4.6 check 37 strings and 38-40 numbers. The Anthropic models are doing more work per document, so their lower hallucination rates are not a volume artifact: they are extracting more values and getting more of them right (or correctly returning null). Hallucination rate normalizes for this, but raw fabricated-values-per-document (in the headline table) does not.
Caveats
Sample size
I ran one packet per difficulty level. That's enough for paired-document claims (same document, five models, same prompts) but not for academic-grade rate estimates. It's why I'm calling this a test, not a benchmark.
Hallucination analyzer threshold
v1 scoring is exact-token: every token in an extracted string has to appear in the source universe, and every extracted number has to match exactly. Earlier versions accepted long compounds at 80% of tokens and numbers within a ±1% band; both rules were dropped because they were one-sided against OpenAI (which fabricates plausible-looking long compounds and numbers near the right magnitude more often than the other providers). Details in scripts/hallucination_analysis.py.
Thinking defaults vary by provider
The three providers disagree on what "default" means: Anthropic's Opus 4.7 and Sonnet 4.6 default to thinking off, OpenAI's GPT-5.4 and GPT-5.5 default to no reasoning_effort parameter (also thinking off), and Google's Gemini 3 defaults to HIGH with no thinking-off mode at all. That's why Gemini is out of the default-effort headline table. Running Gemini-at-HIGH against four thinking-off models wouldn't be a matched comparison. It reappears in the HIGH and XHIGH tables, where all five models are at matched effort. If you want the unmatched default-vs-default view, read across the Default column in the per-effort tables. The raw report has exact API parameter names and values per provider, plus the Anthropic-adaptive-is-opt-in clarification.
Thanks to the anonymous reviewer who flagged this thinking-default gap on the original draft.
Thanks to Apurv Gandhi at Reducto for three catches on the v0 draft and corpus: missing strict-mode schema enforcement, incomplete schema enums (the loss-run status enum was silently nulling Denied / Subrogation / Re-opened claims), and the precision-vs-recall denominator question. All numbers above reflect the v1 corpus (full 148-doc render-source universe) with the v1 scoring refinement: exact-token string match and exact-value numeric match, no fuzzy compound rule, no ±1% numeric band.
Timeouts
Five extractions in the v1 final run could not be completed within the API timeout budget: 4 Sonnet XHIGH and 1 Sonnet HIGH. All five are large N5 documents (3 loss-run variants, the N5 driver schedule, and the N4 loss-run variant for the HIGH miss). Repeated retries with a longer client timeout and a fail-fast diagnostic pass returned the same "request timed out or interrupted" error, so the Anthropic extended-thinking response on those inputs appears to exceed the long-request budget. The two affected cohorts are scored on what completed (n=147 for sonnet_high, n=144 for sonnet_xhigh) and the pivot tables footnote each affected cell. No other provider hit this failure mode. Treat the Sonnet XHIGH column with a discount: the dropped docs are the hardest in the corpus, so the cohort rate is biased low.
Work with me
If you're at an insurance carrier or brokerage, I generate labeled synthetic submission packets against your book at whatever volume you want. Ground truth comes out alongside the rendered document, in the same pass, every field, every location, every line item. No labeling step to staff, no vendor to coordinate with, no calibration calls. Request a sample →
If you run a document-extraction platform, I'll size hard-case packets against the documents you actually work with, or port the generator to your vertical entirely (financial services, legal, healthcare, procurement, whatever you're on). The adversarial-pattern plumbing is already built, so porting is a template change, not a rebuild. Talk about custom packets →
The full 148-document test set is available under research or commercial license. I can also generate at training scale or build custom test sets on request. Licensing or access →
Run it yourself
Test set + scoring pipeline
The public repo nightmare-extraction-test has everything you need to reproduce the headline findings: all 148 documents, ground truth, scoring engine, and prompts.
Match your extractor output to the schema in prompts/, then run scripts/score.py for the per-category composite scores and catastrophic-error counts, and scripts/hallucination_analysis.py for the hallucination pass.
Full hallucination tables, exact API settings per model, and per-model run counts (including timeout exclusions) live in the raw report.
All data is synthetic: no real PII, no real policies, no real companies.